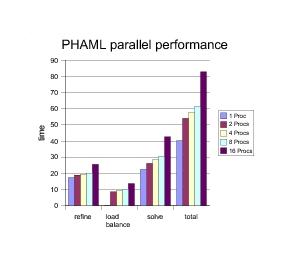
Computation time for phases of PHAML with 1 to 16 processors and 150,000 vertices per processor. At 16 processors, PHAML get about 50% parallel efficiency.
PHAML supports both message passing for distributed memory parallel computers using MPI and shared memory parallelism using OpenMP.
PHAML uses one of six models of parallelism:
The parallelism in PHAML is hidden from the user. One conceptualization is that the computational processes are part of a phaml_solution_type object, and hidden like all the other data in the object. In fact, one of the components of this data structure is a structure that contains information about the parallel processes. The user works only with the master process. In the master/slave model, when the master process calls phaml_create to initialize the data structure, the slave processes are spawned. When the master process calls any of the other public subroutines in module phaml, it sends a message to the slaves with a request to perform the desired operation. When phaml_destroy is called from the master process, the slave processes are terminated.
PHAML was written to be portable not only across different architectures and compilers, but also across different message passing means. All communication between processes is isolated in one module. This module contains the data structures to maintain the information needed about the parallel configuration, and all operations that PHAML uses for communication, such as comm_init, phaml_send, phaml_recv, phaml_alltoall, phaml_global_max, etc. Thus to introduce a new means of message passing, one need only write a new version of this module that adheres to the defined API. PHAML contains versions for MPI 1 (without spawning), MPI 2 (with spawning), and a dummy version for sequential and OpenMP programs.
Publications
Mitchell, W.F., PHAML User's Guide , NISTIR 7374 , 2006. (original, pdf, 3.2M ) (latest revision, pdf)
Mitchell, W.F., The Design of a Parallel Adaptive Multi-Level Code in Fortran 90, Proceedings of the 2002 International Conference on Computational Science, 2002. ( gzipped postscript, 50k)
Last change to this page: December 14, 2011 Date this page created: April 2, 2007 Home Page