
[Home] [Overview] [Performance] [Applications] [Hardware] [Software]
[Related Sites] [Credits]

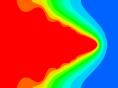
The figure shows a two-dimensional computation of dendritic growth into an undercooled pure liquid using a phase field model. In this computational model, a set of two time-dependent, nonlinear parabolic partial differential equations is solved for the phase field (determines the solidification front) and the driving temperature field in the domain.
The phase field model includes such physical effects as capillarity and interface kinetics. The model equations are solved using straightforward finite difference techniques on a uniform computational mesh.
The figure shows the phase field contours (on the left) and the temperature field (on the right) at one time level in the simulation. The blue regions in the phase-field plots are solid, while the red indicates the undercooled liquid. The thin interfacial layer which is a contruct of the phase-field approach appears as white in the figure. In the temperature plots, red indicates the highest temperature, which for this type of dendritic growth is essentially the freezing temperature of the material. The liquid exists at temperatures below the equilibrium freezing point. The temperature gradients in the liquid are represented by various shades of color from red to blue.
The computation is a very realistic simulation of dendritic growth. It displays the well-established behavior of a parabolic tip region and the formation and development of side-arms.
See here for performance information.
THREEDMD (for "three dimensional matrix decomposition") is a PVM/MPI application which solves an elliptic partial differential equation (PDE) via a "matrix decomposition" technique. (See the following links for references on this technique and implementation.)
The algorithm implemented here is designed to handle elliptic partial differential equations of the form
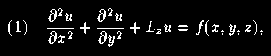
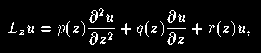
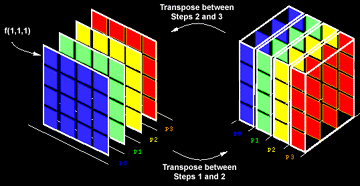
The application basically transforms data into a solution space via (parallel) application of fourier transforms, performs the solution of resulting system of equations (also a parallel step), and the transforms back into the original space via (parallel) inverse fourier transforms. Note: the transforms are themselves sequential, but many are performed in parallel. This is a fast direct method: fast, because it exploits the Fast Fourier Transform, and direct, because the solution is found directly rather than iteratively.
The communication involved is a global matrix transposition between the
initial fourier transform and the solution step, and another transposition
after the solution step before the final inverse transformation.
(Two separate global "all-to-all-personalized" communication steps.)
This project is currently focused on developing a robust distributed memory PVM/MPI-based package for solving certain separable elliptic PDEs in three space variables. A study of communication requirements and performance on the IBM SP2 parallel computer have demonstrated the feasibility of the parallel algorithm for the intended platforms (loosely or tightly coupled Unix workstations running PVM or MPI). Because of the rapidly changing nature of parallel architectures, and the fact that many parallel machines require system specific (non-portable) code, it is often difficult to find publicly available parallel software which is not obsolete. By providing code which uses a portable parallel message-passing library, the investigators hope to increase the usefulness of the research efforts in fields of the specific numerical techniques which they implement.
The current prototype code implements the method of orthogonal spline collocation, and the same parallel methodology can also be used in both finite difference and Galerkin methods for this class of problems. The user interface requirements are under investigation, with the goal of providing a general interface to all three discretization methods and the underlying parallel code implementing each method. This will provide the numerical analysis community with an interesting testbed of solution methods within a parallel context.
See here for performance information.
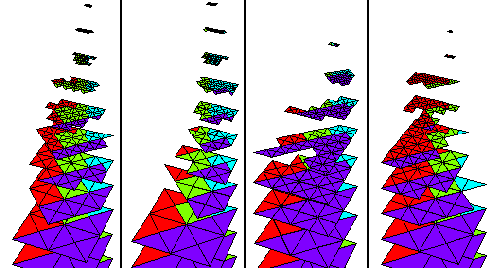
The primary goal of the PHAML project is to produce a parallel version of MGGHAT. The target architecture is distributed memory multiprocessors, such as Jazznet.
MGGHAT is a sequential program for the solution of 2D elliptic partialdifferential equations using low or high order finite elements, adaptive mesh refinement based on newest node bisection of triangles, and multigrid. All aspects of the method are based on the hierarchical basis functions.
Adaptive refinement, multigrid and parallel computing have each been shown to be effective means of vastly reducing the time required to solve differential equations. However, prior to PHAML there has never been a method and program that combines all three techniques.
The PHAML code is begin developed as a prototype implementation. It is written in Fortran 90, which provides modules for modularity and data abstraction, optional arguments for a flexible user interface, and many other useful language features.
PHAML uses a master/slave model of parallel computation. The user program uses the PHAML module, which allows the declaration of variables of type ``phaml_solution'' (a structure containing all the data required by PHAML) and a limited number of operations on those variables. The create operation spawns the slave processes that will operate in parallel when other operations, like solve_pde, are invoked. If graphics options are enabled, additional processes for visualization are also spawned. The processes are terminated by the destroy operation. PHAML uses PVM for message passing (MPI will be added in the future).
The figure illustrates an adaptive multilevel grid on four processors. Each panel shows the grid on one processor. The colors indicate which processor is the ``owner'' of the triangles. From left to right, the processor colors are green, cyan, purple and red. The grids have been separated by refinement level to show the multigrid sequence.
See here for performance information.
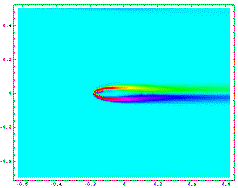
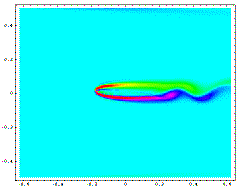
These figures illustrate the flow around an airfoil optimally shaped to minimize the vorticity (maximize the smoothness) of the flow. In the left figure the angle of attack is zero while in the right figure the airfoil is set at a small positive angle of attack. The light blue areas represent smooth flow while the red areas represent regions of greater vorticity.
This project combined numerical simulation of fluid flow around trial shapes with constrained direct search methods to optimize the trial shapes. The Domain Decomposition Method is becoming the method of choice for solving partial differential equations on parallel computers. Here, we employed a domain decomposition and a domain embedding (Fictitious Domain Method) for the numerical simulation of the flow. The constrained direct search method used for optimization was a hybrid algorithm taking advantage of special characteristics of the constraints from the domain decomposition and the domain imbedding. Calculations for both the simulations and the optimizations utilized the parallel architecture of the computers.
For details of the mathematical formulations, consult the following:
See here for performance information.

The Sparse Basic Linear Algebra Subprograms (BLAS) define algorithms for kernel matrix operations which constitute a large portion of numeric codes in differential equations, optimization, and general modeling and simulation.
Current efforts are under way to standardize such interfaces (see the BLAS Technical Forum) and NIST has a preliminary reference implementation underway to study related design and performance issues. Kernel algorithms include
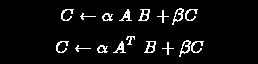
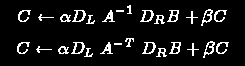
where A is sparse matrix, B and C are dense matrices/vectors, and DL and DR are diagonal matrices. This version of the NIST Sparse BLAS supports the following sparse formats: compressed-row, compressed-column, and coordinate storage formats, together with block and variable-block versions of these. Symmetric and skew-symmetric versions are also supported.
See here for performance information.
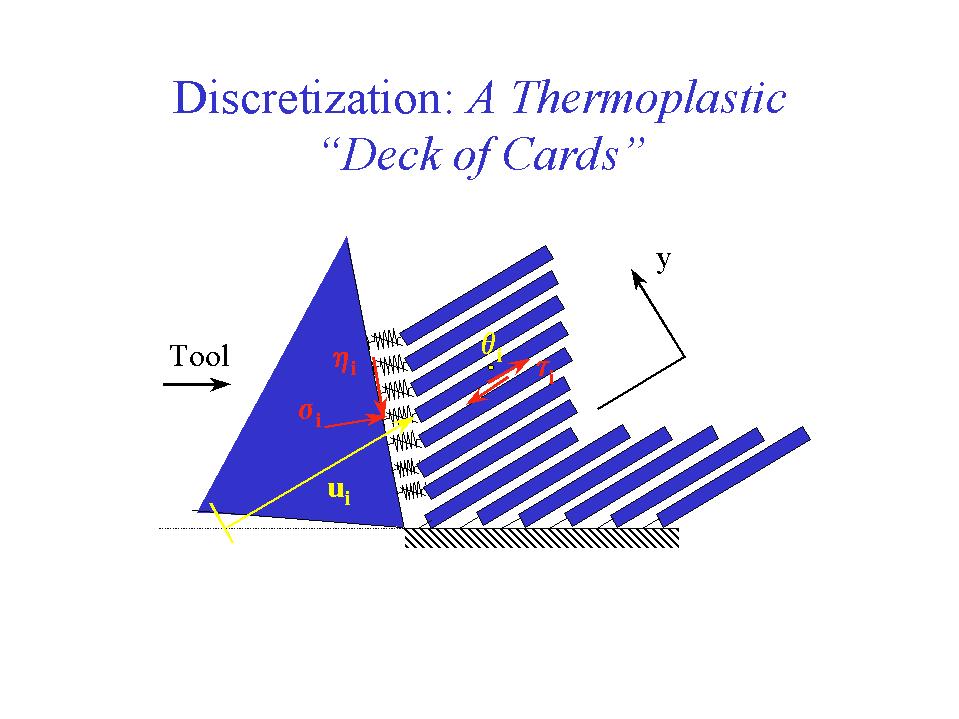
Manfacturers are trying to machine parts which are currently produced by casting or other methods, and at the same time they are also trying to increase cutting speeds. However, these machining speeds are limited by factors such as vibration and tool wear. For these reasons, there is an effort in NIST's Manufacturing Engineering Laboratory (MEL) to develop improved models of high-speed machining, based on a better scientific understanding of these processes.
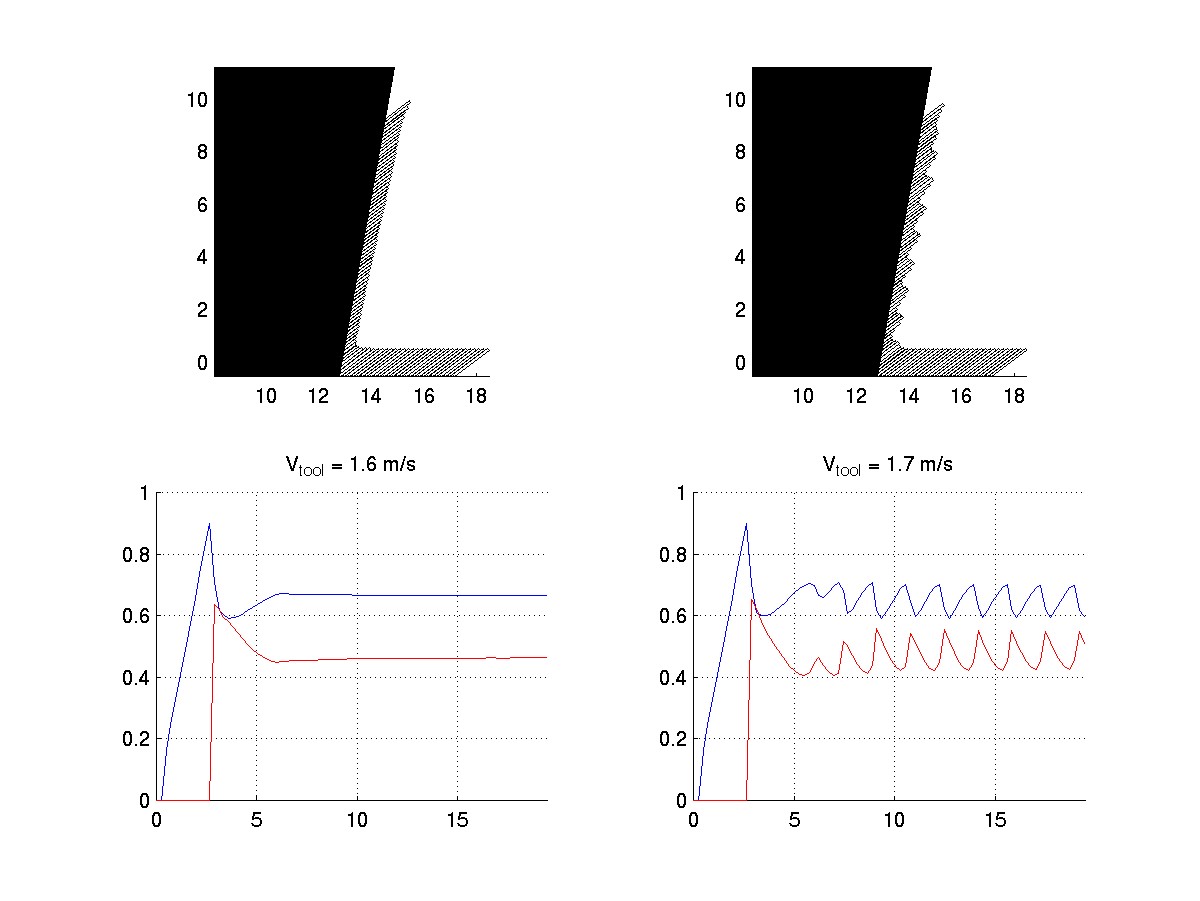
The work shown here comes from an ongoing collaboration between the Automated Production Technology Division in MEL with the Mathematical and Computational Sciences Division in NIST's Information Technology Laboratory (ITL). The first figure depicts a discretization of a one-dimensional mathematical model of rapid orthogonal machining, which is based on ideas from nonlinear dynamics. The thin strip of metal removed by the tool is called a chip. As indicated in the second figure, the model exhibits a bifurcation from continuous to segmented chip formation with increased cutting speed in a steel workpiece, at a speed that is near what has been observed in experiments.
In order to get quick results, the first simulations, shown here, were done using MATLAB. The numerical method of lines was used on a fixed grid with the stiff ODE solver ODE15s of Shampine and Reichelt. The graphs depict the variation with time of the shear stress (upper curves) and the temperature (lower curves) in the workpiece material at the tooltip.
More details of the modeling and analysis may be found in the following two references.
See here for performance information.