ScreenSaver Science ™ (SSS) is a distributed computing
paradigm where useful computations are performed on an organization's
computers whenever their screensavers are on.
In contrast to other distributed computing projects, such as
SETI@Home, the clients of this system, that
is, the part that runs on the user's workstation, will
not consist of a dedicated scientific application.
In the SSS system, the client
will have no particular calculation embedded in it at all, but instead
will be capable of performing any computation, subject to local
resource constraints such as the amount of memory available. This is
made possible through the use of applications compiled to portable
Java bytecode along with the Jini and JavaSpaces technologies
that have been enabled by the Java environment.
Another fundamental difference between SSS and other
distributed computing projects is that SSS clients can communicate
with each other during the computation in order to coordinate the
computation, rather that simply exchanging data with a central job
manager, thus presenting a distributed parallel computing model to the
SSS application programmer.
The need for computing cycles is huge. For a computation that fits
within this paradigm, a huge (usually) untapped resource (an
organization's PC and workstation network) is available to perform the work.
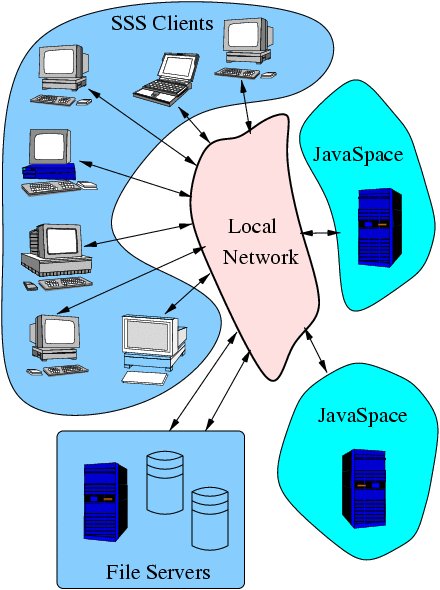
An SSS installation consists of several loosely coupled processes.
The core of the system consists of one or more instances of a
JavaSpace. These "spaces" are used to store tasks to be computed as
well as results from these tasks and any other shared objects needed
by the tasks or the SSS system itself. The current system uses the
JavaSpace provided by Sun Microsystems however this requirement can be
fulfilled by any implementation of the JavaSpace specification. Other
processes in the SSS system include monitors to view the state of the
system as it operates, registration programs to enter users into the
system, and other programs that inspect the spaces and add or remove
objects as needed.
There are two types of participants in SSS: Servers, who compute
SSS tasks on their machines while they would otherwise be idle,
and Clients who submit tasks to be computed.
A person can participate as an SSS Server by registering with the SSS
system. Registration consists of choosing a unique ID for themselves and each
of the machines that will be running the SSS Server. They can then
install the SSS Server on each of their machines. There is actually no
specific screen saver program used by SSS, it simply uses the same
interface into the operating system that is used by the local screen
saver program to control when the SSS Server runs and when it
is killed. Preferences can be given to direct your SSS Servers to
run tasks submitted by specific SSS Clients if there are
any available.
An SSS Client must also register, choosing a unique ID for themselves,
before they can submit tasks into the system. The computational model
presented to the developer of SSS tasks is currently a subject of
research. However, we are targeting large, highly parallel,
scientific applications that can be divided into computational tasks
that can fit on current typical PCs and scientific workstations.
All tasks must consist of pure Java bytecode, typically written
in Java, so that they may run on any participating SSS Server.
Communication between tasks is provided through the same JavaSpace
that is used to hold the SSS objects. Tasks have the same access
to the JavaSpace as the other parts of the SSS system and so may
generate additional tasks if needed, or delete unneeded tasks.
This presents many possibilities to the SSS task programmer.
For example, they may design a "manager" task for their
computation that in turn submits some number of "worker" tasks
and then resubmits itself back into the system before it exits,
to be run again when more worker tasks are needed. Programs can
be run external to the SSS system that can also access the
SSS JavaSpace to monitor and control the execution of tasks.
Data structures shared between tasks can be kept in SSS JavaSpace.
A remote file service has been developed to provide SSS tasks
access to large files for input and output. Each file is represented
by an object that is stored in the SSS JavaSpace and access to remote
files is controlled through those objects. A simple API is used
to open, read, write, and close remote files, using standard
Java input and output streams.
Security will be provided to both SSS Servers and Clients, allowing
for mutual identification and authentication, by technologies
incorporated into the next release of Jini.
|
|
|
 |
Quantum Monte Carlo Studies of Nitrated Organic Compounds
The quantum Monte Carlo (QMC) method is a high accuracy ab
initio method for predicting electronic properties of chemical
systems. The QMC method is highly parallelizable and has relatively
modest computational demands for large systems, compared to methods of
similar accuracy. We are applying QMC to decomposition studies of
methyl nitrates as well as nitrated cubane compounds. Problems of
these sizes are of interest from practical and theoretical
perspectives.
|
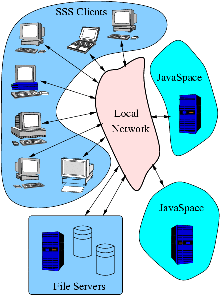 |
| Schematic for Screen Saver Science system. |
|
Papers/Presentations
|
William L. George and Jacob Scott,
Screen Saver Science: Realizing Distributed Parallel Computing with Jini and JavaSpaces
in 2002 Conference on Parallel Architectures and Compilation Techniques (PACT2002), Charlottesville, VA,
September 22-25, 2002.
Links:
postscript and pdf.
|
|
James S. Sims, William L. George, Steven G. Satterfield, Howard K. Hung, John G. Hagedorn, Peter M. Ketcham, Terence J. Griffin, Stanley A. Hagstrom, Julien C. Franiatte, Garnett W. Bryant, W. Jaskolski, Nicos S. Martys, Charles E. Bouldin, Vernon Simmons, Olivier P. Nicolas, James A. Warren, Barbara A. am Ende, John E. Koontz, B. James Filla, Vital G. Pourprix, Stefanie R. Copley, Robert B. Bohn, Adele P. Peskin, Yolanda M. Parker and Judith E. Devaney, Accelerating Scientific Discovery Through Computation
and Visualization II,
NIST Journal of Research, 107
(3)
,
May-June, 2002,
pp. 223-245.
Links:
postscript and pdf.
|
|
|
|